引子
首先我们来看一个看似无用的常识:
一个人正常速度下每分钟可以朗读200-300字(中文);如果是英文,速度也差不多,大概在200个单词左右,换算一下,平均朗读一个单词耗时0.3秒。
这个看似无用的常识,能发挥什么作用呢?
起因
最近我开发了一个YouTube视频字幕转录的web应用,底层的技术很简单,就是通过AI语音模型,将一段音频转录为文字,然后转为字幕文件。
转录时时间粒度一般选择segment,输出的结果是一段一段的,通常来说,一小段应该是一个句子,下面是一个例子,start 和end分表表示这句话的开始和结束时间,text是这段时间内说的话。
```json
{"id": 0,
"start": 0,
"end": 6.1,
"text": " Have you heard the term Zuck-a-saunce?",
...
}
```
但是,转录中经常会遇到这样的问题,一个segment包含了很长的一个时间跨度,对应的文字会非常长,例如:
```json
{"id": 0,
"start": 286,
"end": 297,
"text": "I actually think the main thing that people are going to do, especially because it's open source, is use it as a teacher to train smaller models that they use in different applications.",
...
}
```
如果这段话以字幕的形式展示在视频播放器中,会是这样的:

甚至有时候一段很长的segment对应的字幕,会把整个屏幕铺满。
思路
对于上面遇到的问题,首先想到的是,能不能通过某种方式把这个长句子进行拆分,分割为多个短句,然后将这多个短句的时间对应上就可以了。
不错的思路!
但是问题来了,总不能手动来做吧,AI时代,能用机器解决的问题,一定不要靠体力来解决!
首先,长句拆分为短句,这个事情很简单,LLM可以轻松完成。那么问题就只剩一个了,怎么把拆分后的短句与音频时间匹配上。同样的,这个问题也可以求助AI.
AI 提供了一个思路,根据句子长度,按比例分配时间,只不过AI提供的按比例,是按照字符数的占比来分配时间。例如原句子总共100个字符,时长10秒钟,拆分的一个句子有10个字符,那么对应的时长就是1秒钟。
思路不错,但是太粗暴,还是需要加上人类的常识。对于英文,朗读一段话的时长通常取决于单词数,以及单词的发音,不同单词的发音不同,时长也不同,因此最准确的按比例分配,应该是按照音标分配。
但是我们可以退而求其次,按照单词来分配:假设原文共100个单词,拆分后的一句话有10个单词,那么对应的时长应该是1秒。这种方式有一个前提假设:对比多个句子,每个句子中每个单词的平均朗读时间是相同的。关于这个假设,后面有验证说明。
实现
按照这个思路,我们分两步走:
-
对于超过一定长度的文本,让AI进行拆分,把长句拆分为多个短句,实现这一步只需要一个prompt;
-
根据拆分后的短句单词数,计算每个短句的时长,然后匹配到对应的时间,这一步之需要一段python代码就可以实现。
经过上述两步,我们可以把长句子拆分为多个短句,并且能够正确对其文字与时间戳,下面是一个例子:
原来的转录结果:
``` markdown 66 00:04:46,062 --> 00:04:54,842 I actually think the main thing that people are going to do, especially because it's open source, is use it as a teacher to train smaller models that they use in different applications. ```
处理后的结果:
``` markdown 105 00:04:46,382 --> 00:04:48,622 I actually think the main thing that people are gonna do, 106 00:04:48,622 --> 00:04:52,042 especially because it's open source, is use it as a teacher 107 00:04:52,042 --> 00:04:55,442 to train smaller models that they use in different applications. ```



附录
验证假设
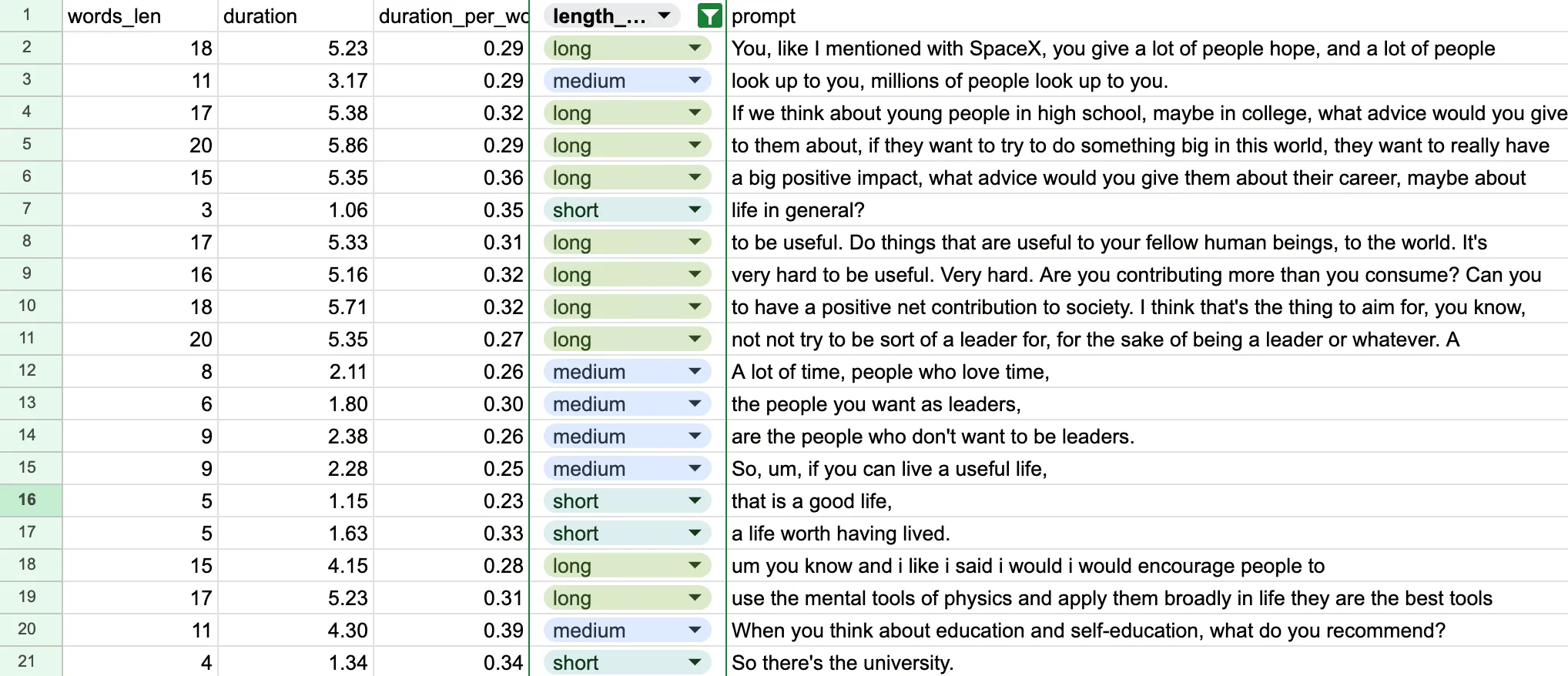
关于开头提到的朗读一个单词的平均时间,这里做了一些统计:随机抽取了74条句子,生成音频,然后计算音频的时长。
在统计时,对句子的长度进行了分组,1-5个单词的句子为sort,5-12为medium,12个单词以上为long。
可以发现,对于超过5个单词的句子,朗读一个单词的平均时间为0.3秒,相对于short组,medium和long这两个分组的数值非常接近。这是因为稍长一点的句子,虽然可能句子中每个单词的朗读时间区别很大,但是整个句子会把均值拉平,这个数据也支撑了使用句子中的单词数来按比例分配时间的做法。
Statistical Analysis:
--------------------------------------------------
Duration per word statistics:
count 74.000000
mean 0.323791
std 0.060297
min 0.230400
25% 0.285750
50% 0.315714
75% 0.347400
max 0.588000
Name: duration_per_word, dtype: float64
Average duration per word by sentence length category:
length_category
short 0.361567
medium 0.304849
long 0.307741
Name: duration_per_word, dtype: float64
另一个小技巧 - 通知策略
做产品经常关注的一件事是,如何让用户持续使用我的产品,产品中最常用的一种功能是通知,通过通知将用户找回。
在设计通知策略时,根据用户的使用习惯来设计通知频率,可以有各种复杂的策略。
但是,有一个简单却非常有效的策略 —— 在用户安装产品后的24小时后进行通知。
这个策略是经过无数次实验得出的,但是仔细一想却很符合直觉,而且基于一个很合理的假设:如果你昨天下午3点有时间,那么大概率今天下午3点也有时间。
简单粗暴,但很有效!
by the way, 这不是我说的,是Duolingo创始人Luis Von Ahn说的!