最近在学英语,发现看老友记能够学到很多地道的表达,于是萌生了一个想法:是否可以通过输入一个场景,来看看老友记中对应的片段?通过这种方式,让学英语变得更加有趣,从技术上来说,其实就是RAG,这个技术已经很成熟了,而且有很多框架提供了方便的接口,做起来应该不难,于是就着手开始,这个项目就这样诞生了。
其实这个项目与chat with pdf这样的项目非常类似,本质上就是提供一个文档,让AI基于文档来回答用户的问题。但是由于文档很长,所以需要先检索到最相关的内容,然后让AI基于这部分内容来回答。
但是,这类项目要做好并不容易,之前负责的产品中也提供过文件对话这样的功能,效果并不理想,最终反而采用了直接采用支持超长上下文的模型,让AI基于全文进行回答,代价就是每次的成本都很高。
所以,我想自己亲自尝试一下,对每一个必要的环节进行优化,看看是否能够达到可用的地步。最终完成后,发现效果还不错,欢迎体验:NativeSpeaker
如果你对RAG或AI感兴趣,或者你有其他想法,欢迎留言讨论。
什么是RAG?
LLMs are trained on enormous bodies of data but they aren’t trained on your data. Retrieval-Augmented Generation (RAG) solves this problem by adding your data to the data LLMs already have access to. —llamaindex
这张图清晰地介绍了RAG的原理,可以查看原文,原文还提供了一个动画,非常便于理解。
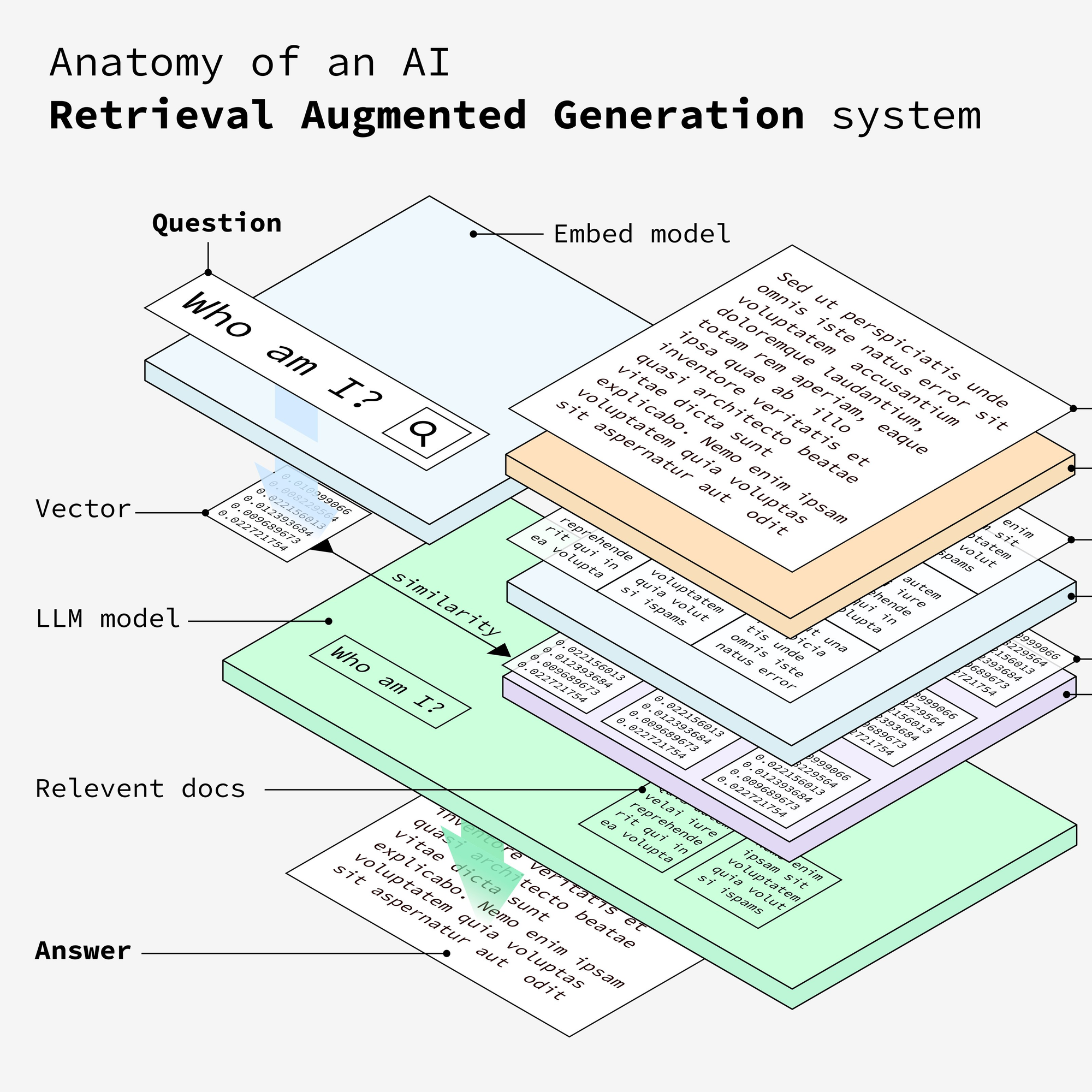
Anatomy of RAG-Retrieval Augmented Generation
我们用这张图上的概念来理解RAG:
- Docs:我们提供的原始文档,目的是让AI基于这份文档提供的内容来回答,图中最右侧的文档部分
- Question:想让AI解答的问题,假设你在跟一个AI对话,这就是你发给AI的问题。
- Embed model:这个模型用于将提供的文档内容进行向量化,向量化的目的是用来计算文档内容与Question之间的相似度。OpenAI目前最好的向量化模型是text-embedding-3-large,详细解释可以参见openai embedding models,还有很多大模型都提供了embed的能力,例如cohere embed
- Vector:提供的docs经过embed model转换之后,会变成向量,其实就是这些文档的数字表示
- LLM model:大语言模型,用来回答问题
- Relevent docs:Docs中与Question最相关的部分文档,这部分文档将作为context发送给LLM,让LLM基于这个context来回答Question
- Answer:LLM最终返回的结果
下面是RAG工作的流程图,主要步骤包括:
- 准备原始文档
- 将原始文档进行拆分,生成多个Documents
- 利用embed model将Documents向量化;
- 将question向量化;
- 计算question与Documents之间的相似度,提取与question最相关的内容;
- 将question和relevant docs发送给LLM,获取答案。
5行代码构建一个RAG应用
在了解了RAG的原理之后,如果要开发一个简单的RAG应用,其实很简单,借助llamaindex,只需要5行代码即可实现。
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader
documents = SimpleDirectoryReader("data").load_data()
index = VectorStoreIndex.from_documents(documents)
query_engine = index.as_query_engine()
response = query_engine.query("What did the author do growing up?")
print(response)
真实世界的RAG
llamaindex、langchain等框架提供了非常方便的接口,可以用几行代码来实现一个RAG应用,但是如果要实现很好的效果,我们还需要很多的优化。下面是我在老友记学英语项目中遇到的一些坑,希望对大家有一定的参考
数据处理
一般来说,纯文本的文档效果最好,因为不需要对图片或视频进行处理,如果是包含图片或视频的pdf或html文档,还需要一些OCR的工作。
下面是我在这个项目中经历的一些数据处理工作:
1. 准备数据 - 数据源1:找到一份老友记ass字幕文件,将文件转为srt格式,去掉多余的格式等内容;
2. 准备数据 - 数据源2:字幕文件不包含对话的角色,导致AI在回答时总是将角色与对话匹配错误,所以又找了一份pdf版本的scripts,包含角色信息与中文翻译;
3. 准备数据 - 数据源2:对pdf scripts进行处理,拆分为多个文件,提取剧集信息作为文件名…
4. 拆分文档 - 对每一集的内容进行拆分,尝试不同的拆分方式(按句子拆分、按页拆分、按token拆分…)
5. 准备数据 - 数据源3:pdf scripts包含的中文翻译导致文件拆分后每一个doc的结果比较混乱,所以又找了一份纯英文的scripts
6. 准备数据 - 数据源3:整理纯英文老友记scripts,清洗数据…
…
文档拆分
不同的文档拆分方式也会影响最终的效果,下面是最常见的一些拆分方式:
- 按句子拆分:例如根据换行符将一个句子作为一个单元,把多个句子作为一个文档;
- 按token拆分:顾名思义,例如把每1000token作为一个文档;
- 根据语义拆分:根据向量相似度,将语义相近的句子作为一个文档;
- …
可以参考textspliter 进一步了解。
在尝试了不同的拆分之后,选择了SentenceSplitter
向量化
这一步主要考虑使用哪个向量模型,我直接用了openai 目前效果最好的embedding model text-embedding-3-large,后续可以尝试其他的模型,例如cohere的向量模型。
由于每一次向量化都有成本,所以在测试过程中取了少量documents来向量化,可以在最终数据准备完成之后再对所有的documents进行向量化。
向量化的结果可以保存到本地,也可以用向量数据库。最开始我把结果保存到本地,但是发现每次加载向量的过程非常耗时,于是尝试了qdrant vector database,速度是相当快!
元数据
有时候metadata也包含了很多信息,例如文件名,document title,page label等。例如我把老友记的每一集剧本放到一个文件里,用文件名来标识哪一季哪一集,把这个信息放到拆分后的每一个doc中,AI在回复的时候就可以参考,有时候是非常有必要的。
prompt
一个好的prompt能够让最终效果提升一个等级,如果使用llamaindex或langchain,默认的prompt可能是这样的:
Context information is below.
---------------------
{context_str}
---------------------
Given the context information and not prior knowledge, answer the query.
Query: {query_str}
Answer:
但是如果想要输出结果更符合我们的预期,可以对prompt进行优化,例如写一个与项目更相关的prompt。
在测试了N次prompt之后,效果终于达到了可以接受的地步,让我们看看这个例子:
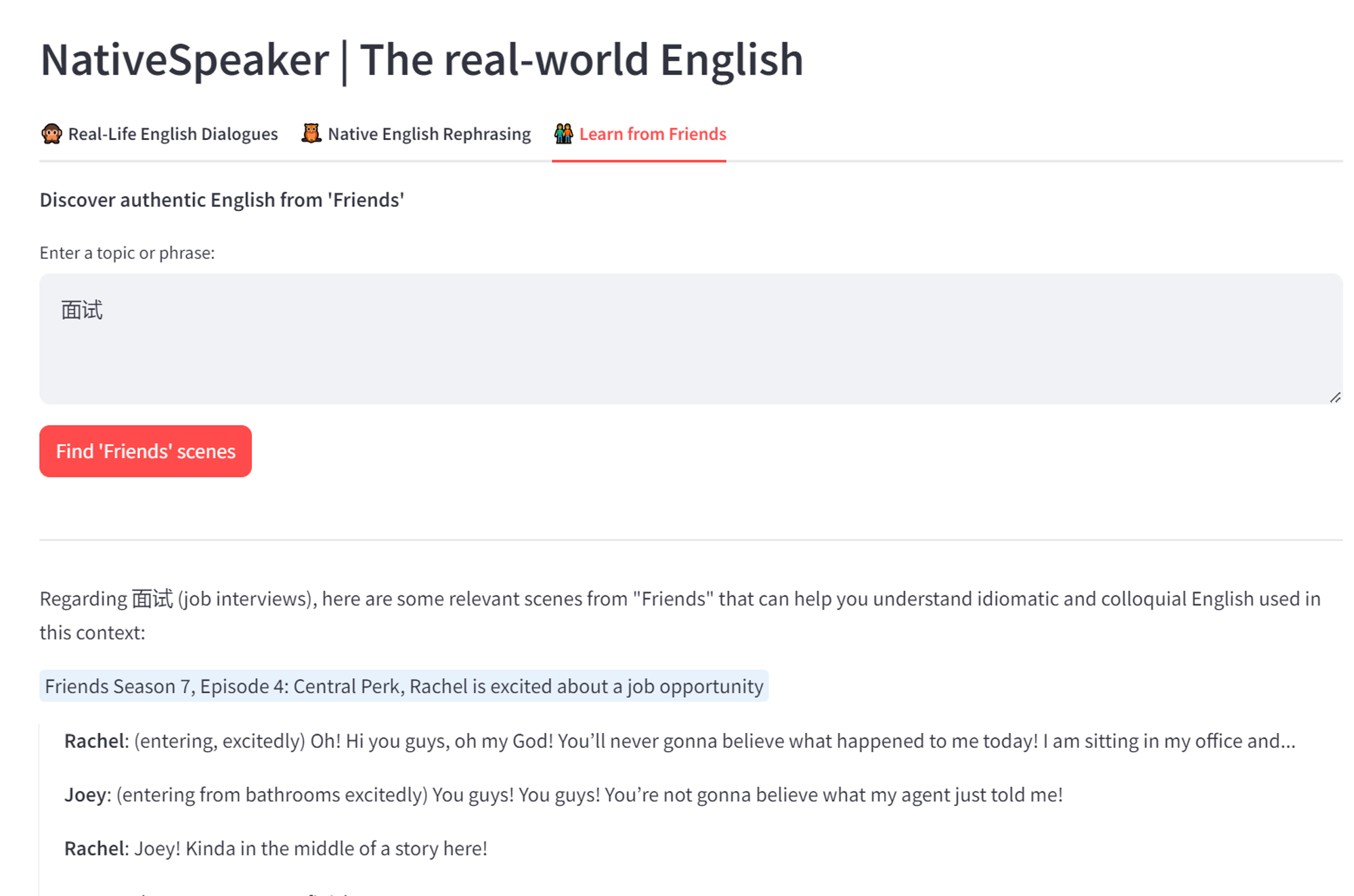
question
可以看到,默认的prompt中有两个参数:
- context_str:即根据相似度计算出来与question最相关的文档
- query_str:即原始输入的question
如果想要效果更好,还可以对question进行处理,例如假设用户输入了一个很简单的短语,如果直接将这个输入去做向量化,然后计算相似度获取context_str,有可能得到的结果与question相关性并不大。
注意,优化question需要与优化prompt一起进行!
最后
以上基本上是我在项目中遇到的所有需要注意的细节,如果你也要用RAG构建应用,欢迎联系我一起讨论。
老友记这个项目仍然还有很大的优化空间,目前还不涉及对图片的处理,也没有涉及到文档关系,对于很多细节也还有待完善。但是作为一个完整的RAG项目,我觉得仍然是一次不错的尝试!
RAG还有很多方向的应用,例如AI客服、AI解读(很多电商详情页已经有了问AI这个功能)、AI搜索,但是底层逻辑都是类似的,核心都在于如何有效地检索相关信息并将其与大语言模型结合。无论是哪种应用场景,关键都在于构建高质量的知识库、设计合适的检索策略,以及优化提示工程以生成准确而有用的回答!