本文来自跟老齐学python,希望从现在开始,重新努力学习python,把这本书中的一些重点积累在这里,一来督促自己学习,二来积攒一些学习的素材和经验。由于是自己学习,本文不会刻意追求排版的优美,只求清晰明了地记录一些自己认为重要的东西。
在此首先表示对老齐的由衷感谢,最近一段时间,我特别觉得,一个人能够把自己努力做出的一些成果无私地分享给其他人,实在是太伟大了,我是打心底里佩服和感谢,希望将来自己也可以通过自己的努力,慢慢地分享一些有用的东西,这是互联网时代,共享让世界更美好!
Day 1
开头
开头的开头,请学会查看官方文档The Python Tutorial
python应用案例https://www.python.org/about/success/
第壹章 基本数据类型
数
在Python中,每个数字都是真实存在的,相对于我们——人类——来讲,它真实存在,它就是对象(object)。
比如整数3,就是一个对象。
每个对象,在内存中都有自己的一个地址,这个就是它的身份。
用内建函数id()可以查看每个对象的内存地址,即身份。用id()得到的内存地址,是只读的,不能修改。
>>> id(3)
140574872
>>> id(3.222222)
140612356
>>> id(3.0)
140612356
>>>
了解了“身份”,再来看“类型”,也有一个内建函数供使用type()。
>>> type(3)
<type 'int'>
>>> type(3.0)
<type 'float'>
>>> type(3.222222)
<type 'float'>
变量
在Python中,有这样一句话是非常重要的:对象有类型,变量无类型。
在Python中,整数可以无限大,但是,浮点数跟整数不同,它存在上限和下限,如果超出了上下的范围,就会出现溢出问题了。
除法
python 2运算
>>> 2 / 5
0
>>> 2.0 / 5
0.4
>>> 2 / 5.0
0.4
>>> 2.0 / 5.0
0.4
在Python 2里面有一个规定,像2/5中的除法这样,是要取整(就是去掉小数,但不是四舍五入)。2除以5,商是0(整数),余数是2(整数)。那么如果用这种形式:2/5,计算结果就是商那个整数。或者可以理解为:整数除以整数,结果是整数(商)。
>>> 5 / 2
2
>>> 7 / 2
3
>>> 8 / 2
4
在Python 3.x中,规则又变了,如果 1/2 ,结果就是0.5,也就是说Python 3中的除法是真正的除法了,要取整,只能用 1//2 的方式,即 1//2=0 。
不管是Python 2还是Python 3,都有这种情况:
>>> 10.0 / 3
3.3333333333333335
>>> 0.1 + 0.2
0.30000000000000004
>>> 0.1 + 0.1 - 0.2
0.0
>>> 0.1 + 0.1 + 0.1 - 0.3
5.551115123125783e-17
>>> 0.1 + 0.1 + 0.1 - 0.2
0.10000000000000003
这是因为计算机在计算的时候,首先要把十进制转换成二进制,而转换时会出现近似,从而造成结果不精确,对于一般的情形,我们只需对结果进行四舍五入即可。
但是如果需要精确的结果,那么可以使用 decimal 模块,它实现的十进制运算适合会计方面的应用和高精度要求的应用。
另外 fractions 模块支持另外一种形式的运算,它实现的运算基于有理数(因此像1/3这样的数字可以精确地表示)。
最高要求则可是使用numPy 包和其它用于数学和统计学的包。
引用模块解决除法
>>> from __future__ import division
>>> 5 / 2
2.5
>>> 9 / 2
4.5
>>> 9.0 / 2
4.5
>>> 9 / 2.0
4.5
注意了,引用了一个模块之后,再做除法,就不管什么情况,都是得到浮点数的结果了。
余数
在Python中(其实大多数语言也都是),用 % 符号来取得两个数相除的余数.
除了使用 % 求余数,还有内建函数 divmod() ——返回的是商和余数。
要实现四舍五入,很简单,就是内建函数: round(),例如round(1.234567, 2) 为1.23
math
import math 引入math模块, dir(module)查看查看模块有哪些方法
第一天就学习到这里,明天继续学习下一节:写一个简单程序
Day2
字符串
python如果要用到中文,需要在文件开头添加#coding:utf-8
连接字符串,用+,python 无法连接不同类型的对象,连接一个int型和一个str型的对象有以下三种方法
a=1998
b="hello"
print b+`a` #尽量不用这种方式
print b+ str(a)
or
print b+ repr(a)
python 中\`通常被看做转义符,有时候为了使用其原始含义,需要使用转义符,例如
>>> dos = "c:\news"
>>> dos
'c:\news' #这里貌似没有什么问题
>>> print dos #当用print来打印这个字符串的时候,就出问题了。
c:
ews
用转义符可以解决
>>> print "c:\\news"
c:\news
or
>>> print r"c:\news"
c:\news
ord() 是一个内建函数,能够返回某个字符(注意,是一个字符,不是多个字符组成的串)所对一个的ASCII值(是十进制的),字符a在ASCII中的值是97,空格在ASCII中也有值,是32。顺便说明,反过来,根据整数值得到相应字符,可以使用 chr() :
字符串格式化
>>> print "I like %s" % "python"
I like python
%现在已经不常用了,现在主要用.format,format 是字符串的一个方法,可以在dir(str)中查到,format方法的作用可以通过帮助文档help(str)来查看
>>>help(str.format)
Help on method_descriptor:
format(...)
S.format(*args, **kwargs) -> string
Return a formatted version of S, using substitutions from args and kwargs.
The substitutions are identified by braces ('{' and '}').
坑爹的字符编码
列表——python中的苦力
>>> a = ['2', 3, 'qiwsir.github.io']
>>> a
['2', 3, 'qiwsir.github.io']
>>> type(a)
<type 'list'>
>>> bool(a)
True
>>> print a
['2', 3, 'qiwsir.github.io']
常用的列表函数
两个让列表扩容的函数 append() 和 extend() ,它们的共同点是“都能原地修改列表”。对于“原地修改”还应该增加一个理解——没有返回值。
原地修改没有返回值,就不能赋值给某个变量。
>>> one = ["good","good","study"]
>>> another = one.extend(["day","day","up"]) #对于没有提供返回值的函数,如果要这样,结果是:
>>> print anthor #打印变量another的值。如果是Python3则输入print(another)
None #返回为None, one.extend()没有返回值,即是None.
>>> one
['good', 'good', 'study', 'day', 'day', 'up']
- list.remove(x) 中的参数是列表中元素,即删除某个元素,且对列表原地修改,无返回值
- list.pop([i]) 中的i是列表中元素的索引值,可选。为空则删除列表最后一个,否则删除索引为i的元素。并且将删除元素作为返回值。
反转
还是通过举例来演示反转的方法:
>>> alst = [1, 2, 3, 4, 5, 6]
>>> alst[: : -1] #反转
[6, 5, 4, 3, 2, 1]
>>> alst
[1, 2, 3, 4, 5, 6]
对于字符串也可以:
>>> lang
'python'
>>> lang[::-1]
'nohtyp'
>>> lang
'python'
Python还有另外一种方法让列表反转,是比较容易理解和阅读的,特别推荐之:
>>> list(reversed(alst))
[6, 5, 4, 3, 2, 1]
>>> list(reversed("abcd"))
['d', 'c', 'b', 'a']
>>> help(reversed)
Help on class reversed in module __builtin__:
class reversed(object)
| reversed(sequence) -> reverse iterator over values of the sequence
|
| Return a reverse iterator
split and join
str.split()
“[sep]”.join(list)
元组
>>> t = 123, 'abc', ["come","here"]
>>> t
(123, 'abc', ['come', 'here'])
元组中的元素不能更改,这点上跟列表不同,倒是跟str类似;它的元素又可以是任何类型的数据,这点上跟列表相同,但不同于字符串。
特别提醒,如果一个元组中只有一个元素的时候,应该在该元素后面加一个半角的英文逗号。
>>> a = (3)
>>> type(a)
<type 'int'>
>>> b = (3,)
>>> type(b)
<type 'tuple'>
所有在列表中可以修改列表的方法,在元组中,都失效。因为元组不可修改。
分别用 list() 和 tuple() 能够实现两者的转化:
>>> t = (1, '23', [123, 'abc'], ('python', 'learn'))
>>> tls = list(t) #tuple-->list
>>> tls
[1, '23', [123, 'abc'], ('python', 'learn')]
>>> t_tuple = tuple(tls) #list-->tuple
>>> t_tuple
(1, '23', [123, 'abc'], ('python', 'learn'))
一般认为,元组有这类特点,并且是它使用的情景:
-
元组比列表操作速度快。如果您定义了一个值的常量集,并且唯一要用它做的是不断地遍历它,请使用元组代替列表。
-
如果对不需要修改的数据进行 “写保护”,可以使代码更安全。使用元组而不是列表如同拥有一个隐含的 assert 语句,说明这一数据是常量。如果必须要改变这些值,则需要执行元组到列表的转换 (需要使用一个特殊的函数)。
-
元组可以在字典(又一种对象类型,后面要讲述) 中被用做 key,但是列表不行。字典的key 必须是不可变的。元组本身是不可改变的,列表是可变的。
-
元组可以用在字符串格式化中。
字典
字符串格式化输出
这是一个前面已经探讨过的话题,请参看《字符串(4)》,这里再次提到,就是因为用字典也可以实现格式化字符串的目的。
>>> city_code = {"suzhou":"0512", "tangshan":"0315", "hangzhou":"0571"}
>>> " Suzhou is a beautiful city, its area code is %(suzhou)s" % city_code
' Suzhou is a beautiful city, its area code is 0512'
>>> temp = "<html><head><title>%(lang)s<title><body><p>My name is %(name)s.</p></body></head></html>"
>>> my = {"name":"qiwsir", "lang":"python"}
>>> temp % my
'<html><head><title>python<title><body><p>My name is qiwsir.</p></body></head></html>'
集合
它的特点是:有的可变,有的不可变;元素无次序,不可重复。
可变的集合:以set()建立的集合可变
不可变的集合:以frozenset()建立的集合不可变
Day 3
第贰章 语句和文件
内建函数zip
>>> c = [1, 2, 3]
>>> d = [9, 8, 7, 6]
>>> zip(c, d) #这是Python 2的结果,如果是Python 3,请仿照前面的方式显示查看
[(1, 9), (2, 8), (3, 7)]
or
>>> result = [(2, 11), (4, 13), (6, 15), (8, 17)]
>>> zip(*result)
[(2, 4, 6, 8), (11, 13, 15, 17)]
>>> myinfor = {"name":"qiwsir", "site":"qiwsir.github.io", "lang":"python"}
>>> dict(zip(myinfor.values(), myinfor.keys()))
{'python': 'lang', 'qiwsir.github.io': 'site', 'qiwsir': 'name'}
内建函数enumerate
>>> week = ['monday', 'sunday', 'friday']
>>> for i in range(len(week)):
... print week[i]+' is '+str(i) #注意,i是int类型,如果和前面的用+连接,必须是str类型
... #如果使用Python 3,请自行更换为print(week[i]+' is '+str(i))
monday is 0
sunday is 1
friday is 2
内建函数enumerate,能够实现类似的功能,并且简化。
>>> for (i, day) in enumerate(week):
... print day+' is '+str(i) #Python 3: print(day+' is '+str(i))
...
monday is 0
sunday is 1
friday is 2
>>> seasons = ['Spring', 'Summer', 'Fall', 'Winter']
>>> list(enumerate(seasons))
[(0, 'Spring'), (1, 'Summer'), (2, 'Fall'), (3, 'Winter')]
>>> list(enumerate(seasons, start=1))
[(1, 'Spring'), (2, 'Summer'), (3, 'Fall'), (4, 'Winter')]
神奇的List comprehensions
>>> squares = [x**2 for x in range(1, 10)]
>>> squares
[1, 4, 9, 16, 25, 36, 49, 64, 81]
>>> mybag = [' glass',' apple','green leaf '] #有的前面有空格,有的后面有空格
>>> [one.strip() for one in mybag] #去掉元素前后的空格
['glass', 'apple', 'green leaf']
>>> week = ['monday', 'sunday', 'friday']
>>>[day+' is ' + str(i) for i,day in enumerate(week)]
>>>['monday is 0', 'sunday is 1', 'friday is 2']
Day 4
while…else
while...else 有点类似 if ... else ,只需要一个例子就可以理解。 当然,一遇到 else 了,就意味着已经不在while循环内了。
count = 0
while count < 5:
print count, " is less than 5"
count = count + 1
else:
print count, " is not less than 5"
for…else
除了有 while...else 外,还可以有 for...else 。这个循环也通常用在当跳出循环之后要做的事情。
# coding=utf-8
from math import sqrt
for n in range(99, 1, -1):
root = sqrt(n)
if root == int(root):
print n
break
else:
print "Nothing."
文件
读文件
>>> f = open("130.txt") #打开已经存在的文件
>>> for line in f:
... print line #Python 3: print(line)
...
learn python
http://qiwsir.github.io
qiwsir@gmail.com
声明:文件130.txt必须在当前目录下,否则需要引用相对路径
在原文中,每行结束有本行结束符号 \n ,表示换行。 print line 或者 print(line) 默认情况下,打印完 line 的对象之后会增加一个 \n 。这样看来,在每行末尾就有两个 \n ,即: \n\n ,于是在打印中就出现了一个空行。print 后面加个,就可以去掉空格
>>> f = open('130.txt')
>>> for line in f:
... print line, #Python 3: print(line, end='')
...
learn python
http://qiwsir.github.io
qiwsir@gmail.com
创建文件
>>> nf = open("131.txt", "w") # w表示以写方式打开文件,可向文件写入信息。如文件存在,则清空该文件,再写入新内容
>>> nf.write("This is a file")
>>> nf.close() #记得每次写完之后都要关闭文件
在对文件进行写入操作之后,一定要牢记一个事情: file.close() ,这个操作千万不要忘记
有另外一种方法,能够不用这么让人揪心,实现安全地关闭文件。
>>> with open("130.txt","a") as f: # a表示以追加模式打开文件(即一打开文件,文件指针自动移到文件末尾),如果文件不存在则创建
... f.write("\nThis is about 'with...as...'")
...
>>> with open("130.txt","r") as f:
... print f.read()
...
learn python
http://qiwsir.github.io
qiwsir@gmail.com
hello
This is about 'with...as...'
>>>
用 open() 操作文件,可以有不同的模式。
| 模式 | 描述 |
|---|---|
| r | 以读方式打开文件,可读取文件信息。 |
| w | 以写方式打开文件,可向文件写入信息。如文件存在,则清空该文件,再写入新内容 |
| a | 以追加模式打开文件(即一打开文件,文件指针自动移到文件末尾),如果文件不存在则创建 |
| r+ | 以读写方式打开文件,可对文件进行读和写操作。 |
| w+ | 消除文件内容,然后以读写方式打开文件。 |
| a+ | 以读写方式打开文件,并把文件指针移到文件尾。 |
| b | 以二进制模式打开文件,而不是以文本模式。该模式只对Windows或Dos有效,类Unix的文件是用二进制模式进行操作的。 |
文件的状态
>>> import os
>>> file_stat = os.stat("131.txt") #查看这个文件的状态
>>> file_stat #文件状态是这样的。从下面的内容,有不少从英文单词中可以猜测出来。
posix.stat_result(st_mode=33204, st_ino=5772566L, st_dev=2049L, st_nlink=1, st_uid=1000, st_gid=1000, st_size=69L, st_atime=1407897031, st_mtime=1407734600, st_ctime=1407734600)
>>> file_stat.st_ctime #这个是文件创建时间
1407734600.0882277
这是什么时间?看不懂!别着急,换一种方式。在Python中,有一个模块 time ,是专门针对时间设计的。
>>> import time
>>> time.localtime(file_stat.st_ctime) #这回看清楚了。
time.struct_time(tm_year=2014, tm_mon=8, tm_mday=11, tm_hour=13, tm_min=23, tm_sec=20, tm_wday=0, tm_yday=223, tm_isdst=0)
read/readline/readlines
read 全部读取
>>> f = open("you.md")
>>> content = f.read()
>>> content
'You Raise Me Up\nWhen I am down and, oh my soul, so weary;\nWhen troubles come and my heart burdened be;\nThen, I am still and wait here in the silence,\nUntil you come and sit awhile with me.\nYou raise me up, so I can stand on mountains;\nYou raise me up, to walk on stormy seas;\nI am strong, when I am on your shoulders;\nYou raise me up: To more than I can be.\n'
>>> f.close()
readline每次读取一行
>>> f = open("you.md")
>>> f.readline()
'You Raise Me Up\n'
>>> f.readline()
'When I am down and, oh my soul, so weary;\n'
>>> f.readline()
'When troubles come and my heart burdened be;\n'
>>> f.close()
可以用循环语句来完成对全文的读取。
# coding=utf-8
f = open("you.md")
while True:
line = f.readline()
if not line: #到EOF,返回空字符串,则终止循环
break
print line , #Python 3: print(line, end='')
f.close() #别忘记关闭文件
readlines() 把文件读取为一个列表,列表的每个元素都是一个字符串,每个字符串中的内容就是文件的一行文字,含行末的符号
>>> f = open("you.md")
>>> content = f.readlines()
>>> content
['You Raise Me Up\n', 'When I am down and, oh my soul, so weary;\n', 'When troubles come and my heart burdened be;\n', 'Then, I am still ...]
>>> for line in content:
... print line , #Python 3: print(line, end='')
...
You Raise Me Up
When I am down and, oh my soul, so weary;
When troubles come and my heart burdened be;
Then, I am still and wait here in the silence,
Until you come and sit awhile with me.
You raise me up, so I can stand on mountains;
You raise me up, to walk on stormy seas;
I am strong, when I am on your shoulders;
You raise me up: To more than I can be.
>>> f.close()
读很大的文件 :fileinput 模块
>>> import fileinput
>>> for line in fileinpyt.input('you.md'):
>>> print line,
readline读取之后,指针对到行末,可以用file.seek(size)来重新定位指针,file.tell()让python告诉指针当前的位置。
# seek(offset[, whence])
f=open('you.md')
f.readline()
Out[117]: 'You Raise Me Up\n'
f.seek(4) # whence默认为0,此时指针从开头开始偏移
f.readline()
Out[120]: 'Raise Me Up\n'
f.seek(-5,1) # 当whence为1时,指针东当前位置开始偏移,offset为负则向前偏移,为正则向后偏移
f.readline()
Out[123]: ' Up\n'
f.seek(5,2) # whence=2时,指针从文件末尾开始偏移
f.tell()
Out[125]: 370L
迭代
- 循环(loop),指的是在满足条件的情况下,重复执行同一段代码。比如,while语句。
- 迭代(iterate),指的是按照某种顺序逐个访问列表中的每一项。比如,for语句。
- 递归(recursion),指的是一个函数不断调用自身的行为。比如,以编程方式输出著名的斐波纳契数列。
- 遍历(traversal),指的是按照一定的规则访问树形结构中的每个节点,而且每个节点都只访问一次。
iter
>>> lst = ['q', 'i', 'w', 's', 'i', 'r']
>>> lst_iter = iter(lst)
>>> while True:
... print lst_iter.next() #Python 3: print(lst_iter.__next__())
...
q
i
w
s
i
r
Traceback (most recent call last): #读取到最后一个之后,停止循环
File "<stdin>", line 2, in <module>
StopIteration
检查python对象
名称
>>> dir.__name__ #dir()的名字
'dir'
类型
>>> import types
>>> print types.__doc__
Define names for all type symbols known in the standard interpreter.
Types that are part of optional modules (e.g. array) are not listed.
>>> dir(types)
['BooleanType', 'BufferType', 'BuiltinFunctionType', 'BuiltinMethodType', 'ClassType', 'CodeType', 'ComplexType', 'DictProxyType', 'DictType', 'DictionaryType', 'EllipsisType', 'FileType', 'FloatType', 'FrameType', 'FunctionType', 'GeneratorType', 'GetSetDescriptorType', 'InstanceType', 'IntType', 'LambdaType', 'ListType', 'LongType', 'MemberDescriptorType', 'MethodType', 'ModuleType', 'NoneType', 'NotImplementedType', 'ObjectType', 'SliceType', 'StringType', 'StringTypes', 'TracebackType', 'TupleType', 'TypeType', 'UnboundMethodType', 'UnicodeType', 'XRangeType', '__builtins__', '__doc__', '__file__', '__name__', '__package__']
>>> p = "I love Python"
>>> type(p)
<type 'str'>
>>> if type(p) is types.StringType:
... print "p is a string"
...
p is a string
属性 有时我们只想测试一个或多个属性是否存在。如果对象具有我们正在考虑的属性,那么通常希望只检索该属性。这个任务可以由 hasattr() 和 getattr() 函数来完成.
>>> hasattr(id, '__doc__')
True
>>> print getattr(id, '__doc__')
id(object) -> integer
可调用
>>> callable("a string")
False
>>> callable(dir)
True
实例
>>> print isinstance.__doc__
isinstance(object, class-or-type-or-tuple) -> bool
Return whether an object is an instance of a class or of a subclass thereof.
With a type as second argument, return whether that is the object's type.
The form using a tuple, isinstance(x, (A, B, ...)), is a shortcut for
isinstance(x, A) or isinstance(x, B) or ... (etc.).
>>> isinstance(42, str)
False
>>> isinstance("python", str)
True
子类
在类这一级别,可以根据一个类来定义另一个类,同样地,这个新类会按照层次化的方式继承属性。Python 甚至支持多重继承,多重继承意味着可以用多个父类来定义一个类,这个新类继承了多个父类。 issubclass() 函数使我们可以查看一个类是不是继承了另一个类:
>>> print issubclass.__doc__
issubclass(C, B) -> Boolean
Return whether class C is a subclass (i.e., a derived class) of class B.
>>> class SuperHero(Person): # SuperHero inherits from Person...
... def intro(self): # but with a new SuperHero intro
... """Return an introduction."""
... return "Hello, I'm SuperHero %s and I'm %s." % (self.name, self.age)
...
>>> issubclass(SuperHero, Person)
1
>>> issubclass(Person, SuperHero)
0
python文档
1.文档是一种对软件系统的书面描述; 2.文档应当精确地描述软件系统; 3.软件文档是软件工程师之间用作沟通交流的一种方式; 4.文档的类型有很多种,包括软件需求文档,设计文档,测试文档,用户手册等; 5.文档的呈现方式有很多种,可以是传统的书面文字形式或图表形式,也可是动态的网页形式
第二章语句和文件到此结束,下一节开启新的一章:函数
函数
定义函数
#coding:utf-8
def add_function(a, b):
c = a + b
return c
if __name__ == "__main__":
result = add_function(2, 3)
print result #python3: print(result)
5
定义函数的格式:
def 函数名(参数1,参数2,...,参数n):
函数体(语句块)
几点说明:
- 函数名的命名规则要符合Python中的命名要求。一般用小写字母和单下划线、数字等组合,有人习惯用aaBb的样式,但我不推荐
- def是定义函数的关键词,这个简写来自英文单词define
- 函数名后面是圆括号,括号里面,可以有参数列表,也可以没有参数
- 千万不要忘记了括号后面的冒号
- 函数体(语句块),相对于def缩进,按照python习惯,缩进四个空格
>>> def add(x,y): #定义一个非常简单的函数
... return x+y #缩进4个空格
...
>>> add(2,3) #通过函数,计算2+3
5
在函数add(x,y)中, x 、 y 并没有严格规定其所引用的对象类型。Python中为对象编写接口,而不是为数据类型。
关于命名
Python对命名的一般要求
-
文件名:全小写,可使用下划线
-
函数名:小写,可以用下划线风格单词以增加可读性。如:myfunction,my_example_function。注意:混合大小写仅被允许用于这种风格已经占据优势的时候,以便保持向后兼容。有的人,喜欢用这样的命名风格:myFunction,除了第一个单词首字母外,后面的单词首字母大写。这也是可以的,因为在某些语言中就习惯如此。但我不提倡,这是我非常鲜明的观点。
-
函数的参数:命名方式同变量(本质上就是变量)。如果一个参数名称和Python保留的关键字冲突,通常使用一个后缀下划线会好于使用缩写或奇怪的拼写。
-
变量:变量名全部小写,由下划线连接各个单词。如color = WHITE,this_is_a_variable = 1。
调用函数
下面的若干条,是常见编写代码的注意事项:
1.别忘了冒号。一定要记住复合语句首行末尾输入“:”(if,while,for等的第一行)
2.从第一行开始。要确定顶层(无嵌套)程序代码从第一行开始。
3.空白行在交互模式提示符下很重要。模块文件中符合语句内的空白行常被忽视。但是,当你在交互模式提示符下输入代码时,空白行则是会结束语句。
4.缩进要一致。避免在块缩进中混合制表符和空格。
5.使用简洁的for循环,而不是while or range.相比,for循环更易写,运行起来也更快
6.要注意赋值语句中的可变对象。
7.不要期待在原处修改的函数会返回结果,比如list.append(),这在可修改的对象中特别注意
8.调用函数是,函数名后面一定要跟随着括号,有时候括号里面就是空空的,有时候里面放参数。
9.不要在导入和重载中使用扩展名或路径。
>>> def my_fun():
... print "I am coding." #Python 3的用户请修改为print()
... return
... print "I finished."
...
>>> my_fun()
I am coding.
return 在这里就有了一个作用,结束正在执行的函数,并离开函数体返回到调用位置,有点类似循环中的 break 的作用。
参数收集
世界是不确定的,那么函数参数的个数,也当然有不确定的时候,怎么解决这个问题呢?Python用这样的方式解决参数个数的不确定性。
def func(x, *arg):
print x #Python 3请自动修改为print()的格式,下同,从略。
result = x
print arg #输出通过*arg方式得到的值
for i in arg:
result +=i
return result
print func(1, 2, 3, 4, 5, 6, 7, 8, 9) #赋给函数的参数个数不仅仅是2个
# 运行后得到
1 #这是函数体内的第一个print,参数x得到的值是1
(2, 3, 4, 5, 6, 7, 8, 9) #这是函数内的第二个print,参数arg得到的是一个元组
45 #最后的计算结果
从上面例子可以看出,如果输入的参数个数不确定,其它参数全部通过 *arg ,以元组的形式由arg收集起来
不给那个 *args 传值,也是许可的。例如:
>>> def foo(x, *args):
... print "x:",x #Python 3: print("x:"+str(x))
... print "tuple:",args
...
>>> foo(7)
x: 7
tuple: ()
这时候 *args 收集到的是一个空的元组。
除了用 *args 这种形式的参数接收多个值之外,还可以用**kargs的形式接收数值,不过这次有点不一样:
>>> def foo(**kargs):
... print kargs #Python 3: print(kargs)
...
>>> foo(a=1,b=2,c=3) #注意观察这次赋值的方式和打印的结果
{'a': 1, 'c': 3, 'b': 2}
如果用 **kargs 的形式收集值,会得到dict类型的数据,但是,需要在传值的时候说明“键”和“值”,因为在字典中是以键值对形式出现的。
综合上面的,我们就可以应付各种各样的参数
>>> def foo(x,y,z,*args,**kargs):
... print x #Python 3用户请修改为print()格式,下同
... print y
... print z
... print args
... print kargs
...
>>> foo('qiwsir',2,"python")
qiwsir
2
python
()
{}
>>> foo(1,2,3,4,5)
1
2
3
(4, 5)
{}
>>> foo(1,2,3,4,5,name="qiwsir")
1
2
3
(4, 5)
{'name': 'qiwsir'}
一种优雅的姿势
>>> def add(x, y):
... return x + y
...
#例子
>>> add(2, 3)
5
#或者用以下方式
>>>bar=(2,3)
>>>add(*bar)
5
这是使用一个星号 * ,是以元组形式传值,如果用 ** 的方式,是不是应该以字典的形式呢?理当如此。
>>> def book(author, name):
... print "{0}is writing {1}".format (author,name) #Python 3: print("{0}}is writing {1}".format (author,name))
...
>>> bars = {"name":"Starter learning Python", "author":"Kivi"}
>>> book(**bars)
Kivi is writing Starter learning Python
递归
递归,见递归.
从前有座山,山里有座庙,庙里有个老和尚,正在给小和尚讲故事。故事是什么呢?“从前有座山,山里有座庙,庙里有个老和尚,正在给小和尚讲故事。故事是什么呢?“从前有座山,山里有座庙,庙里有个老和尚,正在给小和尚讲故事。故事是什么呢?……””
递归(英语:Recursion),又译为递回,在数学与计算机科学中,是指在函数的定义中使用函数自身的方法。
斐波那契数列
# coding=utf-8
def fib(n):
"""
This is Fibonacci by Recursion.
"""
if n==0:
return 0
elif n==1:
return 1
else:
return fib(n-1) + fib(n-2)
if __name__ == "__main__":
f = fib(10)
print f #Python 3: print(f)
为了明确递归的过程,下面走一个计算过程(考虑到次数不能太多,就让n=3)
1.n=3,fib(3),自然要走 return fib(3-1) + fib(3-2) 分支
2.先看fib(3-1),即fib(2),也要走else分支,于是计算 fib(2-1) + fib(2-2)
3.fib(2-1)即fib(1),在函数中就要走elif分支,返回1,即fib(2-1)=1。同理,容易得到fib(2-2)=0。将这两个值返回到上面一步。得到 fib(3-1)=1+0=1
4.再计算fib(3-2),就简单了一些,返回的值是1,即fib(3-2)=1
5.最后计算第一步中的结果: fib(3-1) + fib(3-2) = 1 + 1 = 2 ,将计算结果2作为返回值
# coding=utf-8
"""
the better Fibonacci
"""
meno = {0:0, 1:1}
def fib(n):
if not n in meno:
meno[n] = fib(n-1) + fib(n-2)
return meno[n]
if __name__ == "__main__":
f = fib(10)
print f #Python: print(f)
#运行结果
$ python 20402.py
55
传递函数
# coding:utf-8
def convert(func, seq):
return [func(i) for i in seq]
if __name__ == "__main__":
myseq = (111, 3.14, -9.21)
r = convert(str, myseq)
print r #Python 3: print(r)
# coding:utf-8
def convert(func, seq):
return [func(i) for i in seq]
def num(n):
if n%2 == 0:
return n**n
else:
return n*n
if __name__ == "__main__":
myseq = (3, 4, 5)
r = convert(num, myseq)
print r #Python 3: print(r)
嵌套函数
#coding:utf-8
def foo():
def bar():
print "bar() is running"
bar() #显示调用内嵌函数
print "foo() is running"
foo()
#运行结果
bar() is running
foo() is running
如果单独调用bar(),是会报错的,因为bar()函数定义在foo()内部,只在foo()的函数体内生效
def foo():
a = 1
def bar():
b = a + 1
print "b=",b #Python 3的用户请使用print()
bar()
print "a=",a
foo()
#output:
#b= 2
#a= 1
这里运行正常,但是下面的代码就会运行出错了
def foo():
a = 1
def bar():
a = a + 1 #修改之处
print "bar()a=",a
bar()
print "foo()a=",a
foo()
原因在于bar()里面用到了变量a,按照该表达式,Python解析器认定该变量应是在 bar() 内部建立的,而不是引用的外部对象。所以就报错了。
在Python 3中,你可以使用 nonlocal 关键词,如下演示。
def foo():
a = 1
def bar():
nonlocal a
a = a + 1
print("bar()a=",a)
bar()
print("foo()a=",a)
foo()
#output
#bar()a= 2
#foo()a= 2
在编程实践中,嵌套原理可以这样使用:
def maker(n):
def action(x):
return x ** n
return action
在 maker() 函数中, return action 返回的是 action() 函数对象。
f = maker(2)
print f
m = f(3)
print m
#运行结果
9
f 所引用的对象是一个函数对象—— action() 函数对象, print f 就是打印这个函数对象的信息。
初识装饰器
函数——是对象——能够被传递,也能够嵌套。重复一个简单的举例
def foo(fun):
def wrap():
print "start" #Python 3用户请自行更换为print(),下同,从略
fun()
print "end"
print fun.__name__
return wrap
def bar():
print "I am in bar()"
f = foo(bar)
f()
#运行结果
start
I am in bar()
end
bar
这就是向 foo() 传递了函数对象 bar ——你已经熟悉的传递函数。对于这个问题,我们可以换一个写法——仅仅是换一个写法。
def foo(fun):
def wrap():
print "start"
fun()
print "end"
print fun.__name__
return wrap
@foo #增加的内容
def bar():
print "I am in bar()"
@foo 是一个看起来很奇怪的东西,人们常常把类似这种东西叫做语法糖。
语法糖(Syntactic sugar),也译为糖衣语法,是由英国计算机科学家彼得·兰丁发明的一个术语,指计算机语言中添加的某种语法,这种 对语言的功能并没有影响,但是更方便程序员使用。通常来说使用语法糖能够增加程序的可读性,从而减少程序代码出错的机会。(源自《维基 百科》)
如果用上面的方式,我们可以这样执行程序:
>>> bar()
#运行结果
start
I am in bar()
end
bar
以上,就是所谓的装饰器及其应用, foo() 是装饰器函数,使用 @foo 来装饰 bar() 函数。
装饰器本身是一个函数,将被装饰的类(后面会介绍这种东西)或者函数当作参数传递给装饰器函数,如上面所演示的那样。
什么是闭包
闭包是一个函数,并且这个函数具有以下特点:
-
定义在另外一个函数里面(嵌套函数)
-
引用其所在函数环境的自由变量
# coding:utf-8
def parabola(a, b, c):
def para(x):
return a*x**2 + b*x + c
return para
p = parabola(2, 3, 4)
print p(5) #Python 3: print(p(5))
Day 5
几个特殊函数
lambda
>>> numbers = range(10)
>>> lam = lambda x:x+3
>>> n2 = []
>>> for i in numbers:
... n2.append(lam(i))
...
>>> n2
[3, 4, 5, 6, 7, 8, 9, 10, 11, 12]
lambda函数使用方法
lambda arg1, arg2, ...argN : expression using arguments
map
>>> items = [1,2,3,4,5]
>>> squared = []
>>> for i in items:
... squared.append(i**2)
...
>>> squared
[1, 4, 9, 16, 25]
>>> def sqr(x): return x**2
...
>>> map(sqr,items)
[1, 4, 9, 16, 25]
>>> map(lambda x: x**2, items)
[1, 4, 9, 16, 25]
>>> [ x**2 for x in items ] #这个我最喜欢了,一般情况下速度足够快,而且可读性强
[1, 4, 9, 16, 25]
map的参数还可以是多个
>>> lst1 = [1, 2, 3, 4, 5]
>>> lst2 = [6, 7, 8, 9, 0]
>>> lst3 = [7, 8, 9, 2, 1]
>>> map(lambda x,y,z: x+y+z, lst1, lst2, lst3)
[14, 17, 20, 15, 6]
reduce
>>> reduce(lambda x,y: x+y,[1, 2, 3, 4, 5])
15
对比map
>>> list1 = [1,2,3,4,5,6,7,8,9]
>>> list2 = [9,8,7,6,5,4,3,2,1]
>>> map(lambda x,y: x+y, list1,list2)
[10, 10, 10, 10, 10, 10, 10, 10, 10]
练习:有两个list, a = [3,9,8,5,2] , b=[1,4,9,2,6] ,计算:a[0]b[0]+a[1]b[1]+…的结果。
>>> a = [3, 9, 8, 5, 2]
>>> b = [1, 4, 9, 2, 6]
>>> zip(a,b) #复习一下zip,下面的方法中要用到
[(3, 1), (9, 4), (8, 9), (5, 2), (2, 6)]
>>> sum(x*y for x,y in zip(a,b)) #解析后直接求和
133
>>> new_list = [x*y for x,y in zip(a,b)]
>>> #这样也可以:new_tuple = (x*y for x,y in zip(a,b)),与上面的区别,后续会讲到
>>> new_list
[3, 36, 72, 10, 12]
>>> sum(new_list) #或者:sum(new_tuple)
133
>>> reduce(lambda sum,(x,y): sum+x*y,zip(a,b),0) #这个方法是在耍酷呢吗?
133
>>> from operator import add, mul #耍酷的方法也不止一个
>>> reduce(add, map(mul, a, b))
133
>>> reduce(lambda x,y: x+y, map(lambda x,y: x*y, a,b)) #map,reduce,lambda都齐全了,更酷吗?
133
filter
>>> numbers = range(-5,5)
>>> numbers
[-5, -4, -3, -2, -1, 0, 1, 2, 3, 4]
>>> filter(lambda x: x>0, numbers)
[1, 2, 3, 4]
>>> [x for x in numbers if x>0] #与上面那句等效
[1, 2, 3, 4]
>>> filter(lambda c: c!='y', 'lucky') #能不能对应上面文档说明那句话呢?
'luck' #“If iterable is a string or a tuple, the result also has that type;”
编写函数,在开发实践中是非常必要和常见的,一般情况,你写的函数应该是:
1.尽量不要使用全局变量。
2.如果参数是可变类型数据,在函数内,不要修改它。
3.每个函数的功能和目标要单纯,不要试图一个函数做很多事情。
4.函数的代码行数尽量少。
5.函数的独立性越强越好,不要跟其它的外部东西产生关联。
zip()补充
命名空间
全局变量和局部变量
x = 2
def funcx():
x = 9
print "this x is in the funcx:-->", x #Python 3请自动修改为print(),下同,从略
funcx()
print "--------------------------"
print "this x is out of funcx:-->", x
#运行结果
this x is in the funcx:--> 9
--------------------------
this x is out of funcx:--> 2
x = 2
def funcx():
global x #跟上面函数的不同之处
x = 9
print "this x is in the funcx:-->",x
funcx()
print "--------------------------"
print "this x is out of funcx:-->",x
#运行结果
this x is in the funcx:--> 9
--------------------------
this x is out of funcx:--> 9
作用域
Python的作用域是怎么划分的呢?可以划分为四个层级:
1.Local:局部作用域,或称本地作用域
2.Enclosing:嵌套作用域
3.Global:全局作用域
4.Built-in:内建作用域
#coding:utf-8
def outer_foo():
a = 10
def inner_foo():
a = 20
print "inner_foo,a=", a #a=20
#Python 3的读者,请自行修改为print()函数形式,下同,从略
inner_foo()
print "outer_foo,a=", a #a=10
a = 30
outer_foo()
print "a=", a #a=30
#运行结果
inner_foo,a= 20
outer_foo,a= 10
a= 30
命名空间
命名空间是从所定义的命名到对象的映射集合。
不同的命名空间,可以同时存在,当彼此相互独立互不干扰。
命名空间因为对象的不同,也有所区别,可以分为如下几种:
1.本地命名空间(Function&Class: Local Namespaces) :模块中有函数或者类,每个函数或者类所定义的命名空间就是本地命名空间。如果函数返回了结果或者抛出异常,则本地命名空间也结束了。
2.全局命名空间(Module:Global Namespaces):每个模块创建它自己所拥有的全局命名空间,不同模块的全局命名空间彼此独立,不同模块中 相同名称的命名空间,也会因为模块的不同而不相互干扰。
3.内置命名空间(Built-in Namespaces):Python运行起来,它们就存在了。内置函数的命名空间都属于内置命名空间,所以,我们可以在任何 程序中直接运行它们,比如前面的id(),不需要做什么操作,拿过来就直接使用了。
那么程序在查询上述三种命名空间的时候,就按照从里到外的顺序,即:Local Namespaces –> Global Namesspaces –> Built-in Namesspaces
>>> def foo(num,str):
... name = "qiwsir"
... print locals()
...
>>> foo(221,"qiwsir.github.io")
{'num': 221, 'name': 'qiwsir', 'str': 'qiwsir.github.io'}
>>>
关于函数的学习暂时告一段落,接下来将迎接新的篇章,进阶篇,下一节:类
Day 6
类
对象
“Python中的一切都是对象”,不管是字符串、函数、模块还是类,都是对象。“万物皆对象”。
具体地,人也是对象,假设有个王美女,王美女这个对象具有某些特征,眼睛,大;腿,长;皮肤,白。当然,既然是美女,肯定还有别的显明特征,读者可以自己假设去。如果用“对象”的术语来说明,就说这些特征都是她的属性。也就是说属性是一个对象所具有的特征,或曰:是什么。。
王美女除了具有上面的特征之外,她还能做一些事情,比如她能唱歌、会吹拉弹唱等。这些都是她能够做的事情。用“对象”的术语来说,就是她的“方法”。即方法就是对象能够做什么。
任何一个对象都要包括这两部分:属性(是什么)和方法(能做什么)。
面向对象
定义
面向对象程序设计(英语:Object-oriented programming,缩写:OOP)是一种程序设计范型,同时也是一种程序开发的方法。对象指的是类的实例。它将对象作为程序的基本单元,将程序和数据封装其中,以提高软件的重用性、灵活性和扩展性。
面向对象程序设计可以看作一种在程序中包含各种独立而又互相调用的对象的思想,这与传统的思想刚好相反:传统的程序设计主张将程序看作一系列函数的集合,或者直接就是一系列对电脑下达的指令。面向对象程序设计中的每一个对象都应该能够接受数据、处理数据并将数据传达给其它对象,因此它们都可以被看作一个小型的“机器”,即对象。
目前已经被证实的是,面向对象程序设计推广了程序的灵活性和可维护性,并且在大型项目设计中广为应用。 此外,支持者声称面向对象程序设计要比以往的做法更加便于学习,因为它能够让人们更简单地设计并维护程序,使得程序更加便于分析、设计、理解。反对者在某些领域对此予以否认。
类
定义
在面向对象程式设计,类(class)是一种面向对象计算机编程语言的构造,是创建对象的蓝图,描述了所创建的对象共同的属性和方法。
类的更严格的定义是由某种特定的元数据所组成的内聚的包。它描述了一些对象的行为规则,而这些对象就被称为该类的实例。类有接口和结构。接口描述了如何通过方法与类及其实例互操作,而结构描述了一个实例中数据如何划分为多个属性。类是与某个层的对象的最具体的类型。类还可以有运行时表示形式(元对象),它为操作与类相关的元数据提供了运行时支持。
支持类的编程语言在支持与类相关的各种特性方面都多多少少有一些微妙的差异。大多数都支持不同形式的类继承。许多语言还支持提供封装性的特性,比如访问修饰符。类的出现,为面向对象编程的三个最重要的特性(封装性,继承性,多态性),提供了实现的手段。
编写类
首先要明确,类是对某一群具有同样属性和方法的对象的抽象。比如这个世界上有很多长翅膀并且会飞的生物,于是聪明的人们就将它们统一称为“鸟”——这就是一个类,虽然它也可以称作“鸟类”。
新式类和旧式类
旧式类
>>> class AA: #定义类
pass
>>> aa=AA() # aa是类AA的实例
>>> type(AA)
<type 'classobj'>
#查看aa的类型
>>> aa.__class__
<class __main__.AA at 0xb71f017c>
>>> type(aa)
<type 'instance'>
上面aa.__class__和type(aa)返回的结果竟然不一样,太不和谐,于是就有了新式类:
新式类
>>> class BB(object):
... pass
...
>>> bb = BB()
>>> bb.__class__
<class '__main__.BB'>
>>> type(bb)
<class '__main__.BB'>
在本文此后的内容中,所有Python 2代码中的类,都是新式类。
如何定义新式类呢?
第一种定义方法,就是如同前面那样:
>>> class BB(object):
... pass
...
跟旧式类的区别就在于类的名字后面跟上 (object) ,这其实是一种名为“继承”的类的操作,当前的类 BB 是以类 object 为上级的(object被称为父类),即 BB 是继承自类 object 的新类。在python 3中,所有的类自然地都是类 object 的子类,就不用彰显出继承关系了。
第二种定义方法,在类的前面写上这么一句:__metaclass__ == type ,然后定义类的时候,就不需要在名字后面写 (object) 了。
>>> __metaclass__ = type
>>> class CC:
... pass
...
>>> cc = CC()
>>> cc.__class__
<class '__main__.CC'>
>>> type(cc)
<class '__main__.CC'>
创建类
# coding=utf-8
class Person(object):
"""
This is a sample of class.
"""
def __init__(self, name):
self.name = name
def get_name(self):
return self.name
def color(self, color):
d = {}
d[self.name] = color
return d
实例
类是对象的定义,实例才是真实的物件。比如“人”是一个类,但是“人”终究不是具体的某个活体,只有“张三”、“李四”才是具体的物件,但他们具有“人”所定义的属性和方法。“张三”、“李四”就是“人”的实例。
承接前面的类,先写出调用该类的代码。
if __name__ == '__main__':
girl=Person('canglaoshi')
print girl.name
name=girl.get_name()
print name
her_color=girl.color('white')
print her_color
# 运行结果
canglaoshi
canglaoshi
{'canglaoshi': 'white'}
类提供默认行为,是实例的工厂”(源自Learning Python),这句话道破了类和实例的关系。所谓工厂,就是可以用同一个模子做出很多具体的产品。类就是那个模子,实例就是具体的产品。
类属性
对类属性进行总结:
1.类属性跟类绑定,可以自定义、删除、修改值,也可以随时增加类属性
2.类属性不因为实例变化而发生变化
3.每个类都有一些特殊属性,通常情况特殊属性是不需要修改的,虽然有的特殊属性可以修改,比如 C.__doc__
实例属性
>>> class A(object): #Python 3: class A:
... x = 7
...
>>> foo = A()
>>> foo.x
#运行结果
7
实例属性和类属性的一个最大不同,在于实例属性可以随意更改,不用有什么担心(前面我们建议,尽可能不要修改类属性)。
>>> foo.x += 1
>>> foo.x
8
这是把实例属性修改了。但是,类属性并没有因为实例属性修改而变化,正如前文所讲,类属性是跟类绑定,不受实例影响。
>>> A.x
7
那么, foo.x += 1 的本质是什么呢?
其本质是该实例foo又建立了一个新的属性,但是这个属性(新的foo.x)居然与原来的属性(旧的foo.x)重名,所以,原来的foo.x就被“遮盖了”,只能访问到新的foo.x,它的值是8.
>>> foo.x
8
>>> del foo.x
>>> foo.x
7
>>> A.x += 1
>>> A.x
8
>>> foo.x
8
如果是同一个属性 x ,实例属性跟着类属性而改变。
以上所言,是指当类中变量引用的是不可变数据。
如果类中变量引用可变数据,情形会有所不同。因为可变数据能够进行原地修改。
>>> class B(object):
... y = [1, 2, 3] #变量引用的是一个可变对象。
>>> B.y #类属性
[1, 2, 3]
>>> bar = B()
>>> bar.y #实例属性
[1, 2, 3]
>>> bar.y.append(4)
>>> bar.y
[1, 2, 3, 4]
>>> B.y
[1, 2, 3, 4]
>>> B.y.append("aa")
>>> B.y
[1, 2, 3, 4, 'aa']
>>> bar.y
[1, 2, 3, 4, 'aa']
从上面的比较操作中可以看出,当类中变量引用的是可变对象是,类属性和实例属性都能直接修改这个对象,从而影响另一方的值。
以上所显示的实例属性或者类属性,都源自于类中的变量所引用的值,或者说是静态数据,尽管能够通过类或者实例增加新的属性,其值也是静态的。
还有一类实例属性的生成方法,就是在实例创建的时候,通过__init__()初始化函数建立,这种建立则是动态。
self 的作用
class Person(object): #Python 3: class Person:
def __init__(self, name):
self.name = name
print self #Python 3: print(self)
print type(self) #Python 3: print(type(self))
当创建实例时候,首先要执行构造函数,同时就打印新增的两条。结果是:
>>> girl = Person("canglaoshi")
<__main__.Person object at 0x0000000003146C50>
<class '__main__.Person'>
这说明 self 就是类 Person 的实例,再看看刚刚建立的那个实例 girl 。
>>> girl
<__main__.Person object at 0x0000000003146C50>
>>> type(girl)
<class '__main__.Person'>
数据流转
将类实例化,通过实例来执行各种方法,应用实例的属性,是最常见的操作。
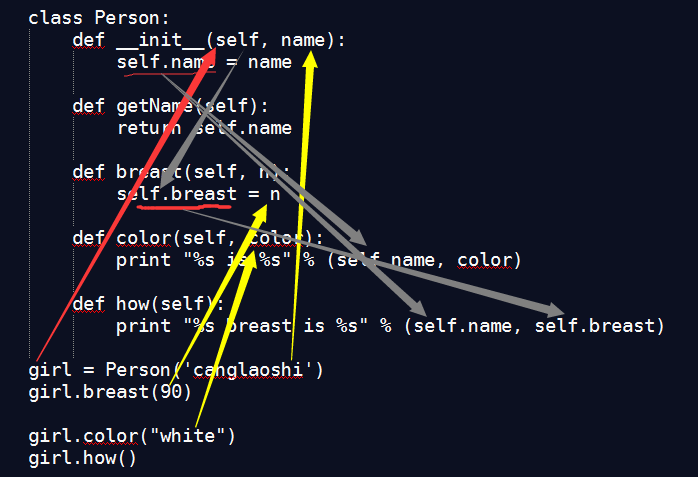
# coding=utf-8
class Person(object): #Python 3: class Person:
def __init__(self, name):
self.name = name
def getName(self):
return self.name
def breast(self, n):
self.breast = n
def color(self, color):
print "%s is %s" % (self.name, color) #Python 3: print("{0} is {1}".format(self.name, color))
def how(self):
print "%s breast is %s" % (self.name, self.breast) #Python 3: print("{0} breast is {1}".format(self.name, self.breast))
girl = Person('canglaoshi')
girl.breast(90)
girl.color("white")
girl.how()
#运行结果
canglaoshi is white
canglaoshi breast is 90
方法
绑定方法和非绑定方法
>>> class Foo: #Python 2: class Foo(object):
def bar(self):
print("This is a normal method of class.") #Python 2 使用print 语句
>>> f = Foo()
>>> f.bar()
This is a normal method of class.
类 Foo 的方法 bar() 也是对象——函数对象,那么,我们就可以像这样来获得该对象了。
>>> Foo.bar
<unbound method Foo.bar> #Python 3的显示结果:<function Foo.bar at 0x00000000006AAC80>
可以很清晰看出,通过类调用的方法对象,是一个非绑定方法——unbound method
此外,还可以通过实例来得到该对象。
>>> f.bar
<bound method Foo.bar of <__main__.Foo object at 0x02A9BFB0>>
用实例来得到这个方法对象,不管是Python 2还是Python 3,结果是一样的。在这里我们看到的是bound method——绑定方法。
综上所述,可以认为:
-
当通过类来获取方法的时候,得到的是非绑定方法对象。
-
当通过实例获取方法的时候,得到的是绑定方法对象。
静态方法和类方法
先看下面的代码
#!/usr/bin/env python
#coding:utf-8
class Foo(object): #Python 3: class Foo:
one = 0
def __init__(self):
Foo.one = Foo.one + 1
def get_class_attr(cls):
return cls.one
if __name__ == "__main__":
f1 = Foo()
print "f1:",Foo.one #Python 3: print("f1:"+str(Foo.one)),下同,从略
f2 = Foo()
print "f2:",Foo.one
print get_class_attr(Foo)
在上述代码中,有一个函数 get_class_attr() ,这个函数的参数我用 cls ,从函数体的代码中看,要求它引用的对象应该具有属性 one ,这就说明,不是随便一个对象就可以的。恰好,就是这么巧,我在前面定义的类 Foo 中,就有 one 这个属性。于是乎,我在调用这个函数的时候,就直接将该类对象传给了它 get_class_attr(Foo) 。
其运行结果如下:
f1: 1
f2: 2
2
在这个程序中,函数 get_class_attr() 写在了类的外面,但事实上,函数只能调用前面写的那个类对象,因为不是所有对象都有那个特别的属性的。所以,这种写法,使得类和函数的耦合性太强了,不便于以后维护。这种写法是应该避免的。避免的方法就是把函数与类融为一体。于是就有了下面的写法。
#!/usr/bin/env python
#coding:utf-8
class Foo(object): #Python 3: class Foo:
one = 0
def __init__(self):
Foo.one = Foo.one + 1
@classmethod
def get_class_attr(cls):
return cls.one
if __name__ == "__main__":
f1 = Foo()
print "f1:",Foo.one
f2 = Foo()
print "f2:",Foo.one
print f1.get_class_attr()
print "f1.one",f1.one
print Foo.get_class_attr()
print "*"* 10
f1.one = 8
Foo.one = 9
print f1.one
print f1.get_class_attr()
print Foo.get_class_attr()
在这个程序中,出现了 @classmethod ——装饰器——在函数那部分遇到过了。需要注意的是 @classmethod 所装饰的方法的参数中,第一个参数不是 self ,这是和我们以前看到的类中的方法是有区别的。这里我使用了参数 cls ,你用别的也可以,只不过习惯用 cls 。
再看对类的使用过程。先贴出上述程序的执行结果:
f1: 1
f2: 2
2
f1.one 2
2
**********
8
9
9
分别建立两个实例,此后类属性 Foo.one 的值是2,然后分别通过实例和类来调用 get_class_attr() 方法(没有显示写 cls 参数),结果都相同。
当修改类属性和实例属性,再次通过实例和类调用 get_class_attr() 方法,得到的依然是类属性的结果。这说明,装饰器 @classmethod 所装饰的方法,其参数 cls 引用的对象是类对象 Foo 。
至此,可以下一个定义了。
所谓类方法,就是在类里面定义的方法,该方法由装饰器 @classmethod 所装饰,其第一个参数 cls 所引用的是这个类对象,即将类本身作为引用对象传入到此方法中。
理解了类方法之后,用同样的套路理解另外一个方法——静态方法。还是先看代码——一个有待优化的代码。
#!/usr/bin/env python
#coding:utf-8
T = 1
def check_t():
T = 3
return T
class Foo(object): #Python 3: class Foo:
def __init__(self,name):
self.name = name
def get_name(self):
if check_t():
return self.name
else:
return "no person"
if __name__ == "__main__":
f = Foo("canglaoshi")
name = f.get_name()
print name #Python 3: print(name)
先观察上面的程序,发现在类 Foo 里面使用了外面定义的函数 check_t() 。这种类和函数的关系,也是由于有密切关系,从而导致程序维护有困难,于是在和前面同样的理由之下,就出现了下面比较便于维护的程序。
#!/usr/bin/env python
#coding:utf-8
T = 1
class Foo(object): #Python 3: class Foo:
def __init__(self,name):
self.name = name
@staticmethod
def check_t():
T = 1
return T
def get_name(self):
if self.check_t():
return self.name
else:
return "no person"
if __name__ == "__main__":
f = Foo("canglaoshi")
name = f.get_name()
print name #Python 3: print(name)
经过优化,将原来放在类外面的函数,移动到了类里面,也就是函数 check_t() 现在位于类 Foo 的命名空间之内了。但是,不是简单的移动,还要在这个函数的前面加上 @staticmethod 装饰器,并且要注意的是,虽然这个函数位于类的里面,跟其它的方法不同,它不以 self 为第一个参数。当使用它的时候,可以通过实例调用,比如 self.check_t() ;也可以通过类调用这个方法,比如 Foo.check_t() 。
从上面的程序可以看出,尽管 check_t() 位于类的命名空间之内,它却是一个独立的方法,跟类没有什么关系,仅仅是为了免除前面所说的维护上的困难,写在类的作用域内的普通函数罢了。但,它的存在也是有道理的,以上的例子就是典型说明。当然,在类的作用域里面的时候,前面必须要加上一个装饰器 @staticmethod 。我们将这种方法也给予命名,称之为静态方法。
方法,是类的重要组成部分。本节专门讲述了方法中的几种特殊方法,它们为我们使用类的方法提供了更多便利的工具。但是,类的重要特征之一——继承,还没有亮相。
Day 7
继承
# coding=utf-8
class Person(object): #Python 3: class Person:
def __init__(self, name):
self.name = name
def height(self, m):
h = dict((["height", m],))
return h
def breast(self, n):
b = dict((["breast", n],))
return b
class Girl(Person):
def get_name(self):
return self.name
if __name__ == "__main__":
cang = Girl("canglaoshi")
print cang.get_name() #Python 3: print(cang.get_name()),下同,从略
print cang.height(160)
print cang.breast(90)
#运行结果
canglaoshi
{'height': 160}
{'breast': 90}
在上面的程序中,子类 Girl 里面没有与父类 Person 重复的属性和方法,但有时候,会遇到这样的情况。
class Girl(Person):
def __init__(self):
self.name = "Aoi sola"
def get_name(self):
return self.name
在子类里面,也写了一个初始化函数,并且定义了一个实例属性 self.name = “Aoi sola” 。在父类中,也有初始化函数。在这种情况下,再次执行程序。
在Python 2中出现异常:
TypeError: __init__() takes exactly 1 argument (2 given)
根源在于,子类 Girl 中的初始化函数,只有一个 self 。因为跟父类中的初始化函数重名,虽然继承了父类,但是将父类中的初始化函数覆盖了,导致父类中的 init() 在子类中不再实现。所以,实例化子类,不应该再显式地传参数。
if __name__ == "__main__":
cang = Girl() #不在显示地传参数
print cang.get_name() #Python 3: print(cang.get_name()),下同,从略
print cang.height(160)
print cang.breast(90)
#修改之后运行结果
Aoi sola
{'height': 160}
{'breast': 90}
从结果中不难看出,如果子类中的方法或属性覆盖了父类(即与父类同名),那么就不在继承父类的该方法或者属性。
像这样,子类 Girl 里面有与父类 Person 同样名称的方法和属性,也称之为对父类相应部分的重写。重写之后,父类的相应部分不再被继承到子类,没有重写的部分,在子类中依然被继承,从上面程序可以看出来此结果。
还有一种可能存在,就是重写之后,如果要在子类中继承父类中相应部分,怎么办?
调用覆盖的方法
封装和私有化
要了解封装,离不开“私有化”,就是将类或者函数中的某些属性限制在某个区域之内,外部无法调用。
Python中私有化的方法也比较简单,就是在准备私有化的属性(包括方法、数据)名字前面加双下划线。例如:
class ProtectMe(object): #Python 3: class ProtectMe:
def __init__(self):
self.me = "qiwsir"
self.__name = "kivi"
def __python(self):
print "I love Python." #Python 3: print("I love Python."),下同,从略
def code(self):
print "Which language do you like?"
self.__python()
if __name__ == "__main__":
p = ProtectMe()
print p.me
print p.__name
#运行结果
qiwsir
Traceback (most recent call last):
File "21102.py", line 21, in <module>
print p.__name
AttributeError: 'ProtectMe' object has no attribute '__name'
报错信息,告诉我们没有 __name 那个属性。果然隐藏了,在类的外面无法调用。再试试那个函数,可否?
if __name__ == "__main__":
p = ProtectMe()
p.code()
p.__python()
#运行结果
Which language do you like?
I love Python.
Traceback (most recent call last):
File "21102.py", line 23, in <module>
p.__python()
AttributeError: 'ProtectMe' object has no attribute '__python'
如愿以偿。该调用的调用了,该隐藏的隐藏了。
用上面的方法,的确做到了封装。但是,我如果要调用那些私有属性,怎么办?
可以使用property函数
# coding=utf-8
class ProtectMe(object): #Python 3: class ProtectMe:
def __init__(self):
self.me = "qiwsir"
self.__name = "kivi"
@property
def name(self):
return self.__name
if __name__ == "__main__":
p = ProtectMe()
print p.name #Python 3: print(p.name)
#运行结果
kivi
从上面可以看出,用了 @property 之后,在调用那个方法的时候,用的是 p.name 的形式,就好像在调用一个属性一样,跟前面 p.me 的格式相同。
定制类
定制类,就要用到类的特殊方法,比如初始化函数 init ,虽然用途很 广泛,但仅仅用它还嫌不够,还要用到其它的特殊方法。
class RoundFloat(object): #Python 3: class RoundFloat:
def __init__(self, val):
assert isinstance(val, float), "value must be a float."
self.value = round(val, 2)
def __str__(self):
return "{:.2f}".format(self.value)
__repr__ = __str__
if __name__ == "__main__":
r = RoundFloat(2.185)
print r #Python 3: print(r)
print type(r) #Python 3: print(type(r))
上述程序中的类 RoundFloat 的作用是定义了一种两位小数的浮点数类型,利用这个类,能够得到两位小数的浮点数。
在初始化函数中 assert isinstance(val, float), "value must be a float." 是对输入的数据类型进行判断,如果不是浮点数就会抛出异常提示。关于 assert (断言)可以参看后续内容。
方法 __str__() 是一个特殊方法。实现这个方法,目的就是能够得到打印的内容。这里就是将前面四舍五入保留了两位小数的浮点数,以小数点后有两位小数的形式输出。
__repr__ = __str__ 的含义是在类被调用,即向变量提供 __str__() 里的内容。
#运行结果
2.19
<class '__main__.RoundFloat'>
Day 8
黑魔法
优化内存的 __slots__
属性拦截
在Python中,有一些方法就具有“拦截”能力。
-
__setattr__(self, name,value):如果要给name赋值,就调用这个方法。 -
__getattr__(self, name):如果name被访问,同时它不存在的时候,此方法被调用。 -
__getattribute__(self, name):当name被访问时自动被调用(注意:这个仅能用于新式类),无论name是否存在,都要被调用。 -
__delattr__(self, name):如果要删除name,这个方法就被调用。
class NewRectangle(object):
def __init__(self):
self.width = 0
self.length = 0
def __setattr__(self, name, value):
if name == "size":
self.width, self.length = value
else:
self.__dict__[name] = value
def __getattr__(self, name):
if name == "size":
return self.width, self.length
else:
raise AttributeError
if __name__ == "__main__":
r = NewRectangle()
r.width = 3
r.length = 4
print r.size #Python 3: print(r.size)
r.size = 30, 40
print r.width #Python 3: print(r.width)
print r.length #Python 3: print(r.length)
想要了解更多黑魔法的知识,可以查看Python Attributes and Methods
迭代器
生成器
定义生成器
>>> def g():
... yield 0
... yield 1
... yield 2
>>> g
<function g at 0xb71f3b8c>
>>> dir(ge)
['__class__', '__delattr__', '__doc__', '__format__', '__getattribute__', '__hash__', '__init__', '__iter__', '__name__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', 'close', 'gi_code', 'gi_frame', 'gi_running', 'next', 'send', 'throw']
yield
首先来看一下return
>>> def r_return(n):
... print "You taked me." #Python 3: print("You taked me."),下同,从略
... while n > 0:
... print "before return"
... return n
... n -= 1
... print "after return"
...
>>> rr = r_return(3)
You taked me.
before return
>>> rr
3
从函数被调用的过程可以清晰看出, rr = r_return(3) ,函数体内的语句就开始执行了,遇到 return ,将值返回,然后就结束函数体内的执行。所以 return 后面的语句根本没有执行。这是 return 的特点
下面将return改为yield:
>>> def y_yield(n):
... print "You taked me." #Python 3: print("You taked me."),下同,从略
... while n > 0:
... print "before yield"
... yield n
... n -= 1
... print "after yield"
...
>>> yy = y_yield(3) #没有执行函数体内语句
>>> yy.next() #Python 3: yy.__next__(),下同,从略
You taked me.
before yield
3 #遇到yield,返回值,并暂停
>>> yy.next() #从上次暂停位置开始继续执行
after yield
before yield
2 #又遇到yield,返回值,并暂停
>>> yy.next() #重复上述过程
after yield
before yield
1
>>> yy.next()
after yield #没有满足条件的值,抛出异常
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
StopIteration
一般的函数,都是止于 return 。作为生成器的函数,由于有了 yield ,则会遇到它挂起。
使用yeild构造斐波那契数列:
def fibs(max):
"""
斐波那契数列的生成器
"""
n, a, b = 0, 0, 1
while n < max:
yield b
a, b = b, a + b
n = n + 1
if __name__ == "__main__":
f = fibs(10)
for i in f:
print i , #Python 3: print(i, end=',')
#运行结果
1 1 2 3 5 8 13 21 34 55
上下文管理器
在《文件(1)》中提到,如果要打开文件,一种比较好的方法是使用 with 语句,因为这种方法,不仅结构简单,更重要的是不用再单独去判断某种异常情况,也不用专门去执行文件关闭的指令了。
首先建立一个文件,名称为23501.txt,里面的内容如下:
hello laoqi
www.itdiffer.com
如果要从一个文件读内容,写入到另外一个文件中,以下代码可以实现:
# coding=utf-8
read_file = open("23501.txt")
write_file = open("23502.txt", "w")
try:
r = read_file.readlines()
for line in r:
write_file.write(line)
finally:
read_file.close()
write_file.close()
用“上下文管理器”可以将上述代码写的更好,用 with 语句改写之后,就是很优雅的了。
with open("23501.txt") as read_file, open("23503.txt", "w") as write_file:
for line in read_file.readlines():
write_file.write(line)